NLP의 기본 절차와 Lexical Analysis_180415_19_00.html
자연언어처리의 기본 절차와 몇 가지 용어에 대해 살펴보도록 하자.
@
자연언어처리의 기본 절차
img fe840022-20ca-48a9-9684-3d96944f827d.png
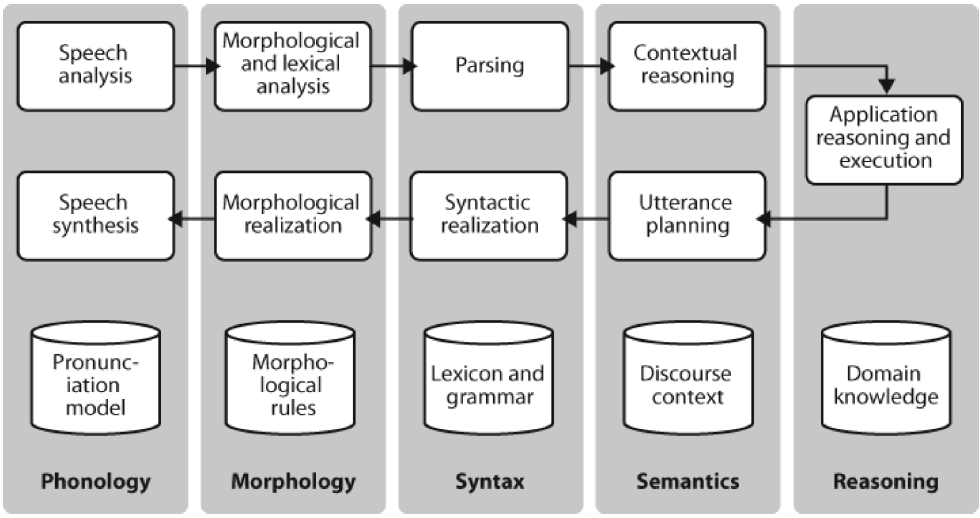 자연언어처리의 전반적인 절차를 간략하게 시각화한 것은 위 그림과 같다.
자연언어처리는 언어학을 근간으로 하고 있다.
언어학은 말소리를 연구하는 음운론(Phonology),
단어와 형태소를 연구하는 형태론(Morphology),
문법과 맥락/담화를 각각 논의하는 통사론(syntax),
의미론(Senmantics) 등 세부 분야가 있다.
자연언어처리 절차와 단계도 이런 구분과 궤를 같이 한다.
다시 말해 음성 인식, 형태소 분석, 파싱(문장의 문법적 구조 분석) 등이,
각각 언어학의 음운/형태/통사론 등에 대응된다는 얘기이다.
구체적인 분석 과정을 도표로 정리한 그림은 다음과 같습니다.
img 5bb4c292-83b6-4589-86ea-d40dbcb805a2.png
자연언어처리의 전반적인 절차를 간략하게 시각화한 것은 위 그림과 같다.
자연언어처리는 언어학을 근간으로 하고 있다.
언어학은 말소리를 연구하는 음운론(Phonology),
단어와 형태소를 연구하는 형태론(Morphology),
문법과 맥락/담화를 각각 논의하는 통사론(syntax),
의미론(Senmantics) 등 세부 분야가 있다.
자연언어처리 절차와 단계도 이런 구분과 궤를 같이 한다.
다시 말해 음성 인식, 형태소 분석, 파싱(문장의 문법적 구조 분석) 등이,
각각 언어학의 음운/형태/통사론 등에 대응된다는 얘기이다.
구체적인 분석 과정을 도표로 정리한 그림은 다음과 같습니다.
img 5bb4c292-83b6-4589-86ea-d40dbcb805a2.png
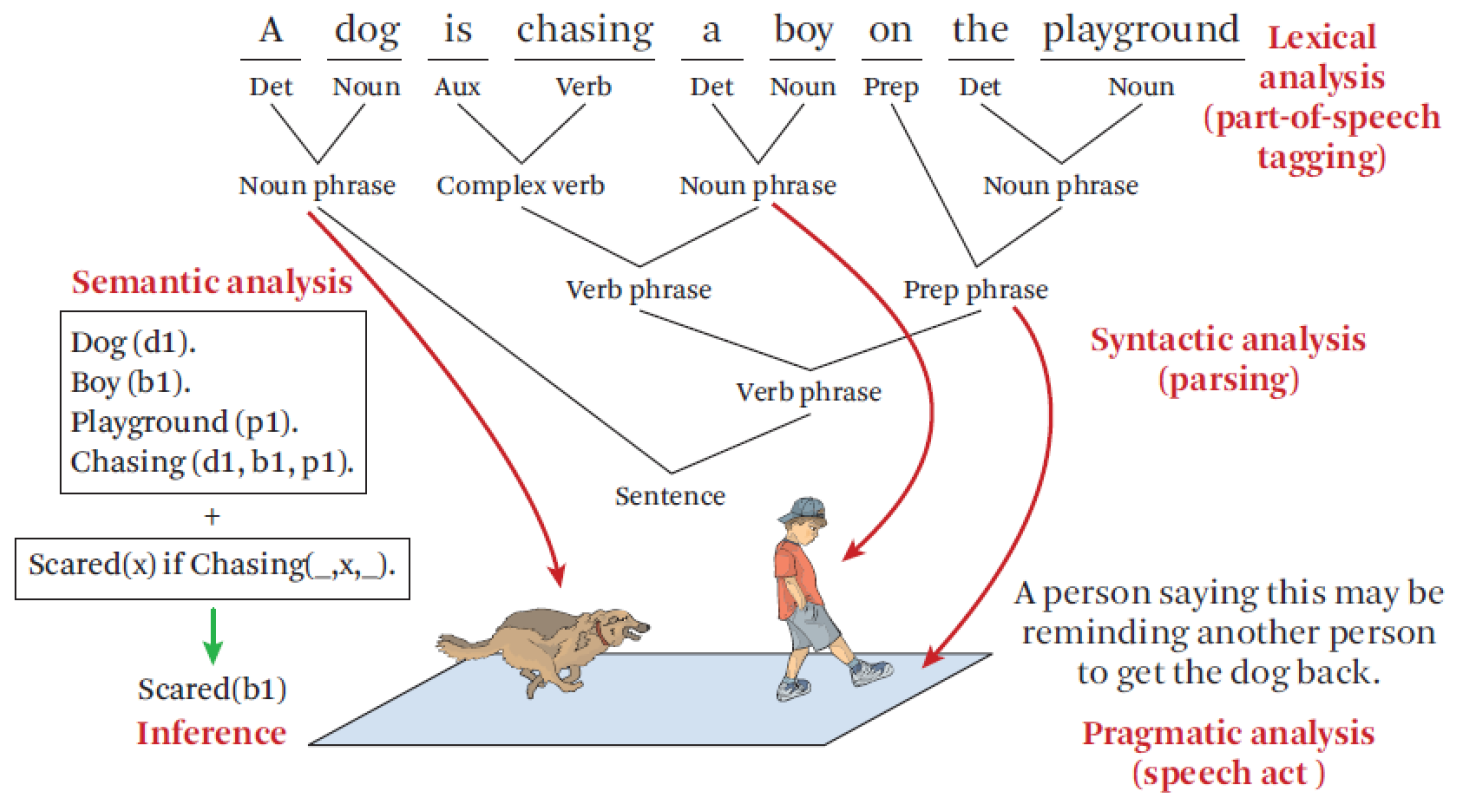 과정별로 나타낸 그림은 다음과 같다.
img 16f7430a-dab6-43f8-9858-94cf619d80ae.png
과정별로 나타낸 그림은 다음과 같다.
img 16f7430a-dab6-43f8-9858-94cf619d80ae.png
 이번 글에서는 어휘분석(Morphological and lexcical analysis) 중심으로 이야기를 해보겠다.
@
어휘분석(Lexical Analysis)
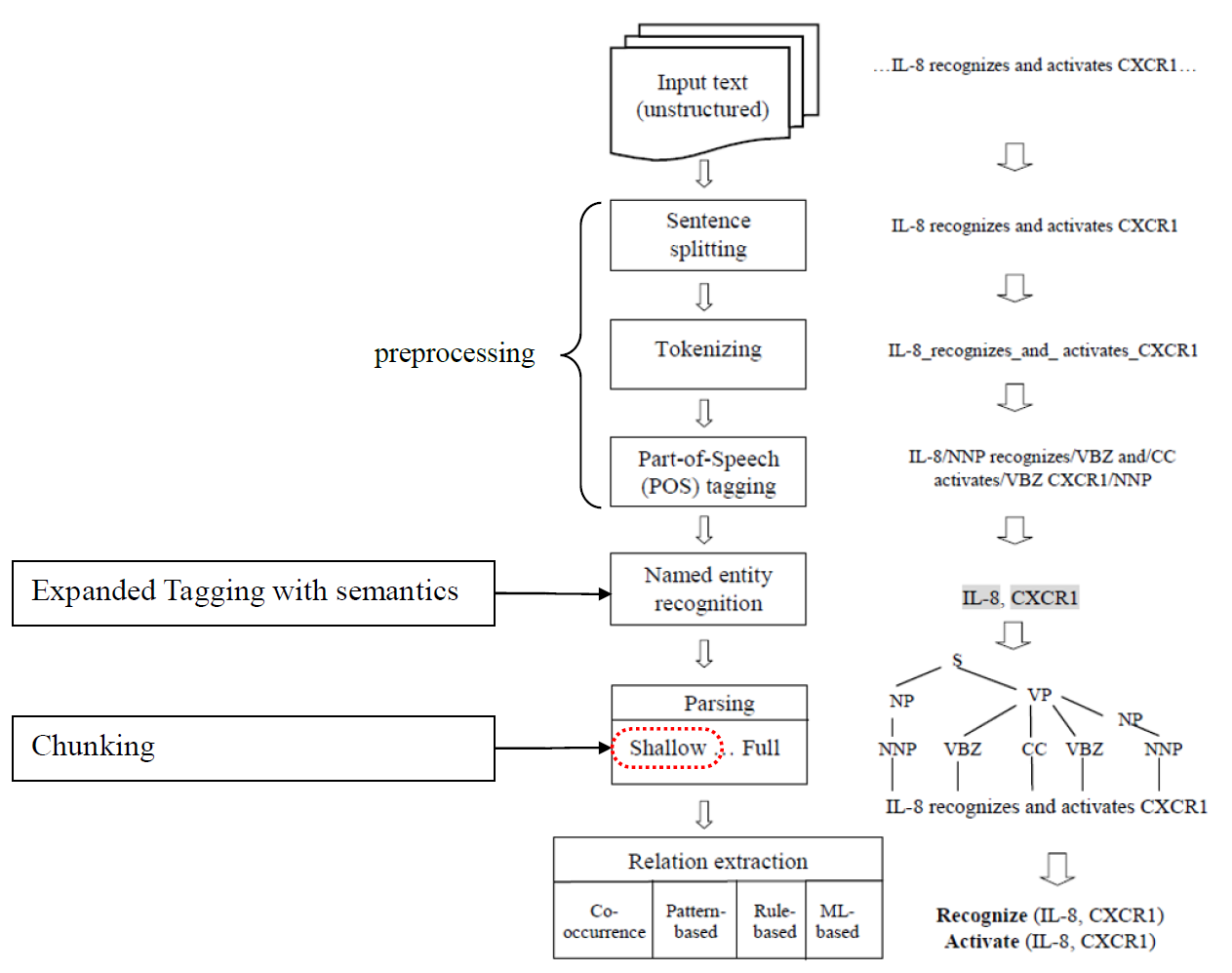
어휘 분석을 한눈에 조망할 수 있는 그림이 바로 아래 예시이다.
img 9dc03f8e-82c6-44ee-a67d-30548077d607.png
이번 글에서는 어휘분석(Morphological and lexcical analysis) 중심으로 이야기를 해보겠다.
@
어휘분석(Lexical Analysis)
어휘 분석을 한눈에 조망할 수 있는 그림이 바로 아래 예시이다.
img 9dc03f8e-82c6-44ee-a67d-30548077d607.png
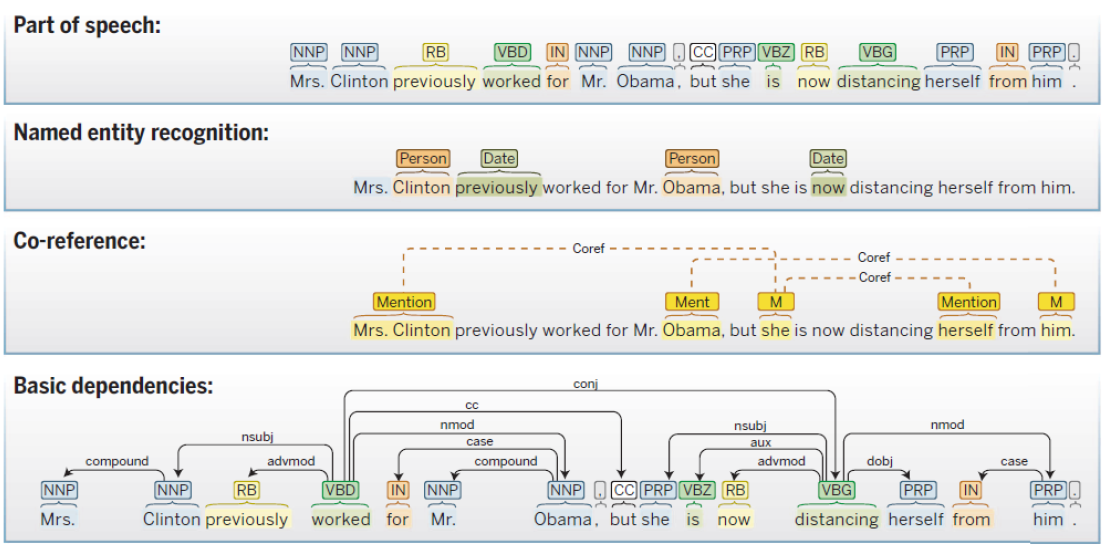 포스태깅(Part of speech)는 단어의 품사 정보를 결정하는 절차이다.
개체명 인식(Named entity recognition)은 인명, 지명 등 고유명사를 분류하는 방법론이다.
상호참조(co-reference)는 선행 단어/구를 현재 단어/구와 비교해 같은 개체인지를 결정하는 문제이다.
의존관계 분석(basic dependencies)은 성분에 따라 문장구조를 정의하는 구구조문법(생성문법 기반)과 달리,
단어와 다른 단어가 가지는 의존관계를 중시해 문장 구조를 분석하는 방법이다.
이들 넷은 모두 어휘분석의 하위 범주이다.
어휘분석
part of speech
named entity recognition
co-reference
basic dependencies
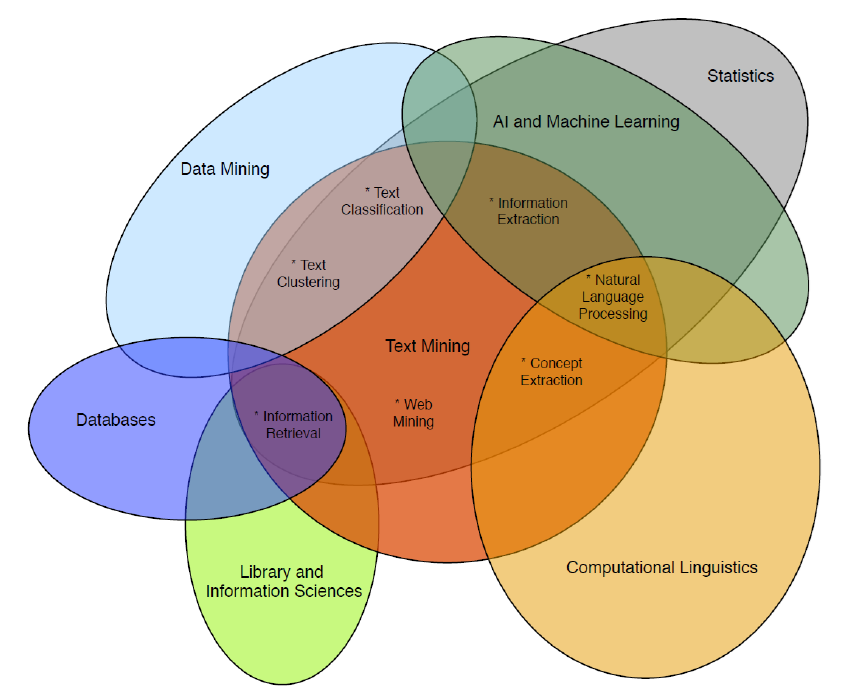
언어학, 통계학, 수학, 컴퓨터사이언스 등 다양한 분야의 학자들이 꽤 많은 성과를 낸 영역이다.
자연언어처리는 이들 영역이 모두 겹쳐있는 융합학문이다.
img 5bb07c6a-1db7-465f-a4bf-db2f2b333435.png
포스태깅(Part of speech)는 단어의 품사 정보를 결정하는 절차이다.
개체명 인식(Named entity recognition)은 인명, 지명 등 고유명사를 분류하는 방법론이다.
상호참조(co-reference)는 선행 단어/구를 현재 단어/구와 비교해 같은 개체인지를 결정하는 문제이다.
의존관계 분석(basic dependencies)은 성분에 따라 문장구조를 정의하는 구구조문법(생성문법 기반)과 달리,
단어와 다른 단어가 가지는 의존관계를 중시해 문장 구조를 분석하는 방법이다.
이들 넷은 모두 어휘분석의 하위 범주이다.
어휘분석
part of speech
named entity recognition
co-reference
basic dependencies
언어학, 통계학, 수학, 컴퓨터사이언스 등 다양한 분야의 학자들이 꽤 많은 성과를 낸 영역이다.
자연언어처리는 이들 영역이 모두 겹쳐있는 융합학문이다.
img 5bb07c6a-1db7-465f-a4bf-db2f2b333435.png
 @
어휘분석 절차
문장분리(sentence splitting), 토크나이즈(tokenize), Morphological analysis, 포스태깅 네 단계로 나뉜다.
@
Sentence splitting
컴퓨터 입장에서 말뭉치(corpus)는 의미없는 글자들의 연속된 나열일 것이다.
우선 분절된 의미를 전달하기 위해 말뭉치를 문장 단위로 끊어서 입력해야 한다.
일반적으로, 마침표(.), 느낌표(!), 물음표(?) 등 기준으로도 충분히 문장분리를 잘 수행할 수 있다.
하지만 토픽모델링 같은 특정 알고리즘이나 방법론의 경우 문장분리를 반드시 수행하지 않아도 된다.
@
Tokenize
토큰(token)이란 의미를 가지는 문자열(string)을 뜻힌다.
토큰은 형태소(뜻을 가진 최소 단위)나,
형태소보다 상위 개념인 단어(자립하여 쓸 수 있는 최소 단위)까지 포함한다.
토크나이징(tokenizing)이란 문서나 문장을 분석하기 좋도록 토큰으로 나누는 작업이다.
영어의 경우 공백만으로도 충분히 토큰을 나눌 수 있다고 한다.
물론 ‘-‘(state-of-the-art vs state of the art)이나 합성어(Barack Obama) 등 처리를,
세밀히 해줘야 하는 문제가 남아있긴 하다.
띄어쓰기를 거의 하지 않는 중국어의 경우 토큰 분석 작업이 난제로 꼽힌다.
@
Morphological analysis
Text Normaization 이라고 불리기도 한다.
토큰들을 좀 더 일반적인 형태로 분석해 단어수를 줄여 분석의 효율성을 높이는 작업이다.
예컨대 ‘cars’ 와 ‘car’, ‘stopped’ 와 ‘stop’ 을 하나의 단어로 본다던지 하는 식이다.
영어에선 대문자를 소문자로 바꿔주는 folding 도 이와 관련된 중요한 작업이라고 한다.
stemming 과 lemmatization 이라는 작업도 있다.
stemming 이란 단어를 축약형으로 바꿔주는 걸 뜻한다.
lemmatization 은 품사 정보가 보존된 형태의 기본형으로 변환하는 걸 말한다.
아래 표가 두 기법 차이를 잘 드러내고 있습니다.
Word stemming lemmatization
Love Lov Love
Loves Lov Love
Loved Lov Love
Loving Lov Love
Innovation Innovat Innovation
Innovations Innovat Innovation
Innovate Innovat Innovate
Innovates Innovat Innovate
Innovative Innovat Innovative
@
Part-Of-Speech Tagging
포스태깅이란 각 토큰에 품사정보를 할당하는 작업이다.
포스태깅을 위해 많은 방법론들이 개발되었다.
의사결정나무(Decision Trees),
은닉 마코프 모델(Hidden Markov Models),
서포트벡터머신(Support Vector Machines) 등이 여기에 해당한다.
KoNLPy 같은 한국어 기반의 포스태거들은 문장분리, 토크나이즈, lemmatization, 포스태깅에 이르기까지,
전 과정을 한꺼번에 수행해 준다.
하지만 조사, 어미가 발달한 한국어의 경우 정확한 분석이 어렵다.
한국어는 교착어 성질을 지니는 언어이기 때문이다.
즉, 어근에 파생접사나 어미가 붙어서 단어를 이룬다.
바꿔 말하면 한국어를 분석할 때 어근과 접사, 어미를 적절하게 나누어야 하는데,
이게 쉽지 않다는 얘기이다.
예를 들면 이렇다.
깨뜨리시었겠더군요.
여기에서 ‘깨-‘는 어근이며,
‘-뜨리-‘는 접사로서 ‘힘줌’의 뜻을 나타낸다.
‘-시-‘는 높임,
‘-었-‘, ‘-겠-‘, ‘-더-‘는 모두 시간을 보이는 어미들이다.
‘-군-‘은 감탄의 뜻을 나타내는 어미이다.
‘-요’는 문장을 끝맺는 어미이다.
위 문장을 제대로 분석하려면 8개 형태소로 쪼개야 한다. 이것은 매우 고된 작업이다.
@
마치며
이상으로 자연언어처리의 기본 절차를 어휘분석 중심으로 살펴보았다.
정리하면서 느낀 건데 단어와 형태소 분석이 자연언어처리의 기본 중 기본 아닐까 하는 생각이 든다.
이 작업이 신통치 않다면 이를 기반으로 하는 파싱(문장 구조 분석) 등 이후 과정의 신뢰도가 무너지게 될 것이기 때문이다.
더 나은 방법이 없을까 늘 고민해보겠다.
@
어휘분석 절차
문장분리(sentence splitting), 토크나이즈(tokenize), Morphological analysis, 포스태깅 네 단계로 나뉜다.
@
Sentence splitting
컴퓨터 입장에서 말뭉치(corpus)는 의미없는 글자들의 연속된 나열일 것이다.
우선 분절된 의미를 전달하기 위해 말뭉치를 문장 단위로 끊어서 입력해야 한다.
일반적으로, 마침표(.), 느낌표(!), 물음표(?) 등 기준으로도 충분히 문장분리를 잘 수행할 수 있다.
하지만 토픽모델링 같은 특정 알고리즘이나 방법론의 경우 문장분리를 반드시 수행하지 않아도 된다.
@
Tokenize
토큰(token)이란 의미를 가지는 문자열(string)을 뜻힌다.
토큰은 형태소(뜻을 가진 최소 단위)나,
형태소보다 상위 개념인 단어(자립하여 쓸 수 있는 최소 단위)까지 포함한다.
토크나이징(tokenizing)이란 문서나 문장을 분석하기 좋도록 토큰으로 나누는 작업이다.
영어의 경우 공백만으로도 충분히 토큰을 나눌 수 있다고 한다.
물론 ‘-‘(state-of-the-art vs state of the art)이나 합성어(Barack Obama) 등 처리를,
세밀히 해줘야 하는 문제가 남아있긴 하다.
띄어쓰기를 거의 하지 않는 중국어의 경우 토큰 분석 작업이 난제로 꼽힌다.
@
Morphological analysis
Text Normaization 이라고 불리기도 한다.
토큰들을 좀 더 일반적인 형태로 분석해 단어수를 줄여 분석의 효율성을 높이는 작업이다.
예컨대 ‘cars’ 와 ‘car’, ‘stopped’ 와 ‘stop’ 을 하나의 단어로 본다던지 하는 식이다.
영어에선 대문자를 소문자로 바꿔주는 folding 도 이와 관련된 중요한 작업이라고 한다.
stemming 과 lemmatization 이라는 작업도 있다.
stemming 이란 단어를 축약형으로 바꿔주는 걸 뜻한다.
lemmatization 은 품사 정보가 보존된 형태의 기본형으로 변환하는 걸 말한다.
아래 표가 두 기법 차이를 잘 드러내고 있습니다.
Word stemming lemmatization
Love Lov Love
Loves Lov Love
Loved Lov Love
Loving Lov Love
Innovation Innovat Innovation
Innovations Innovat Innovation
Innovate Innovat Innovate
Innovates Innovat Innovate
Innovative Innovat Innovative
@
Part-Of-Speech Tagging
포스태깅이란 각 토큰에 품사정보를 할당하는 작업이다.
포스태깅을 위해 많은 방법론들이 개발되었다.
의사결정나무(Decision Trees),
은닉 마코프 모델(Hidden Markov Models),
서포트벡터머신(Support Vector Machines) 등이 여기에 해당한다.
KoNLPy 같은 한국어 기반의 포스태거들은 문장분리, 토크나이즈, lemmatization, 포스태깅에 이르기까지,
전 과정을 한꺼번에 수행해 준다.
하지만 조사, 어미가 발달한 한국어의 경우 정확한 분석이 어렵다.
한국어는 교착어 성질을 지니는 언어이기 때문이다.
즉, 어근에 파생접사나 어미가 붙어서 단어를 이룬다.
바꿔 말하면 한국어를 분석할 때 어근과 접사, 어미를 적절하게 나누어야 하는데,
이게 쉽지 않다는 얘기이다.
예를 들면 이렇다.
깨뜨리시었겠더군요.
여기에서 ‘깨-‘는 어근이며,
‘-뜨리-‘는 접사로서 ‘힘줌’의 뜻을 나타낸다.
‘-시-‘는 높임,
‘-었-‘, ‘-겠-‘, ‘-더-‘는 모두 시간을 보이는 어미들이다.
‘-군-‘은 감탄의 뜻을 나타내는 어미이다.
‘-요’는 문장을 끝맺는 어미이다.
위 문장을 제대로 분석하려면 8개 형태소로 쪼개야 한다. 이것은 매우 고된 작업이다.
@
마치며
이상으로 자연언어처리의 기본 절차를 어휘분석 중심으로 살펴보았다.
정리하면서 느낀 건데 단어와 형태소 분석이 자연언어처리의 기본 중 기본 아닐까 하는 생각이 든다.
이 작업이 신통치 않다면 이를 기반으로 하는 파싱(문장 구조 분석) 등 이후 과정의 신뢰도가 무너지게 될 것이기 때문이다.
더 나은 방법이 없을까 늘 고민해보겠다.